Tomcat架构原理

文章目录
Tomcat整体架构
Tomcat的启动流程如下:
startup.sh -> catalina.sh start -> java -jar org.apache.catalina.startup.Bootstrap.main()
Tomcat需要实现的2个核心功能:
- 处理socket连接,负责网络字节流与Request和Response对象的转化;
- 加载并管理Servlet,以及处理具体的Request请求;
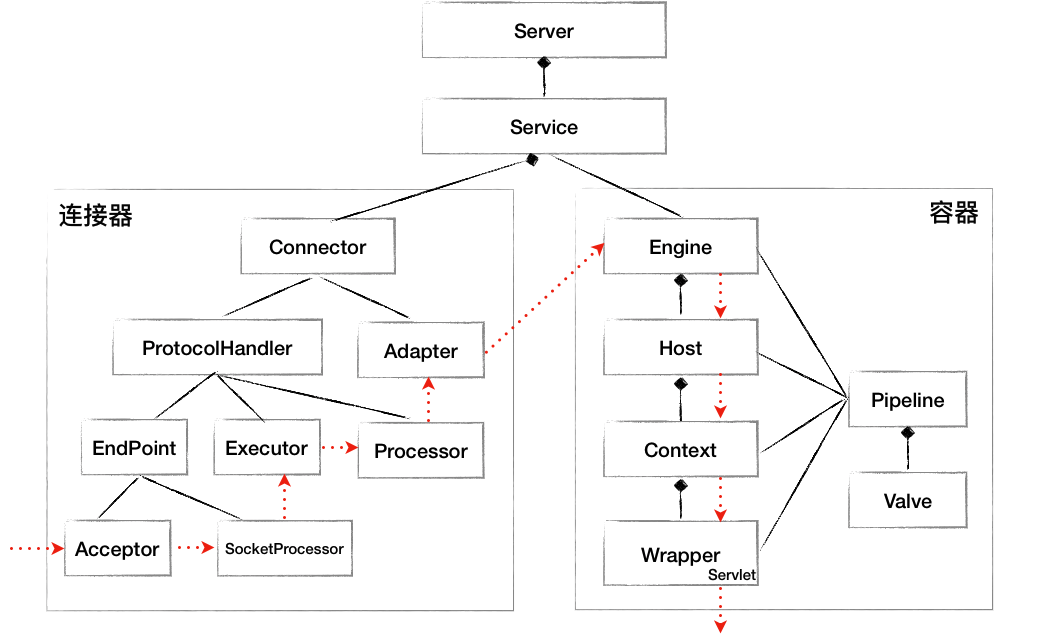
为此,Tomcat设计了两个核心组件: 连接器(Connector)和容器(Container) ,连接器负责对外交流,容器负责内部处理;同时,tomcat为了实现支持多种IO模型和应用层协议, 一个容器可能对接多个连接器 ,好比一个房间有多个们。
Tomcat的整体架构图如下图所示:
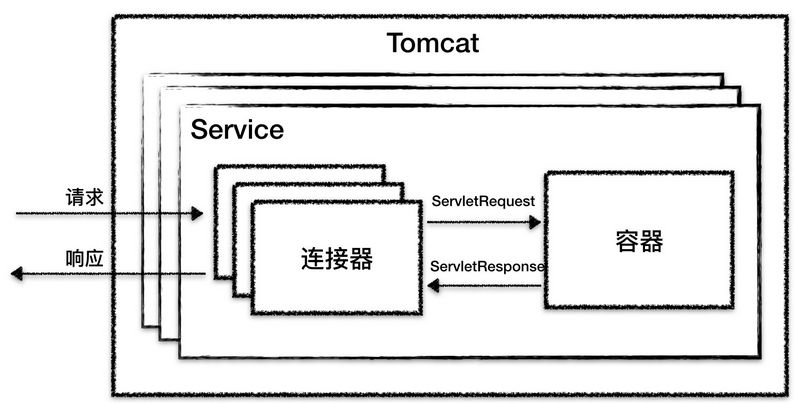
- Server对应就是一个Tomcat实例;
- Service 默认 只有一个,也就是一个Tomcat实例默认一个Service;
- Connector:一个Service可能多个连接器,接收不同的连接协议;
- Container:多个连接器对应一个容器,顶层容器其实就是Engine;
每个组件都有对应的生命周期,需要启动的话,还需要启动自己内部的子组件,比如一个Tomcat实例包含一个Service,一个Service包含多个连接器和一个容器。而一个容器又包含多个Host,Host内部可能有多个Context容器,而一个Context也会包含多个Servlet。整体是一个俄罗斯套娃。
Connecter
Tomcat支持的IO模型有:
- NIO:非阻塞IO,采用Java NIO类库实现;
- NIO2:异步IO,采用JDK7最新的的NIO2类库实现;
- APR:采用Apache可移植运行库实现,是C/C++编写的本地库;
Tomcat支持的应用层协议有:
- HTTP/1.1:绝大部分WEB应用采用的访问协议;
- AJP:用于和WEB服务器集成;
- HTTP/2:HTTP 2.0大幅度提升了WEB性能;
所以一个容器可能对接多个连接器,连接器对Servlet容器屏蔽了网络协议和IO模型的区别,无论是HTTP还是AJP,在容器中获取到的都是一个标准的ServletRequest对象;
细化连接器的功能就是:
- 监听网络端口;
- 接收网络连接请求;
- 读取请求网络字节流;
- 根据具体的应用层协议解析字节流,生成统一的Tomcat Request对象;
- 将Tomcat Request对象转换成标准的ServletRequest对象;
- 调用Servlet容器,得到ServletResponse对象;
- 将ServletResponse转成Tomcat Response对象;
- 将Tomcat Response转成网络字节流;
- 将响应字节流写回给浏览器;
其中,Tomcat设计了三个组件,其负责功能如下:
- EndPoint:负责网络通信,将字节流传递给Processor;
- Processor:负责处理字节流生成Tomcat Request对象,将Tomcat Request对象传递给Adapter;
- Adapter:负责将Tomcat Request对象转成ServletRequest对象,传递给容器;
再细化一下连接器,得到如下架构图:
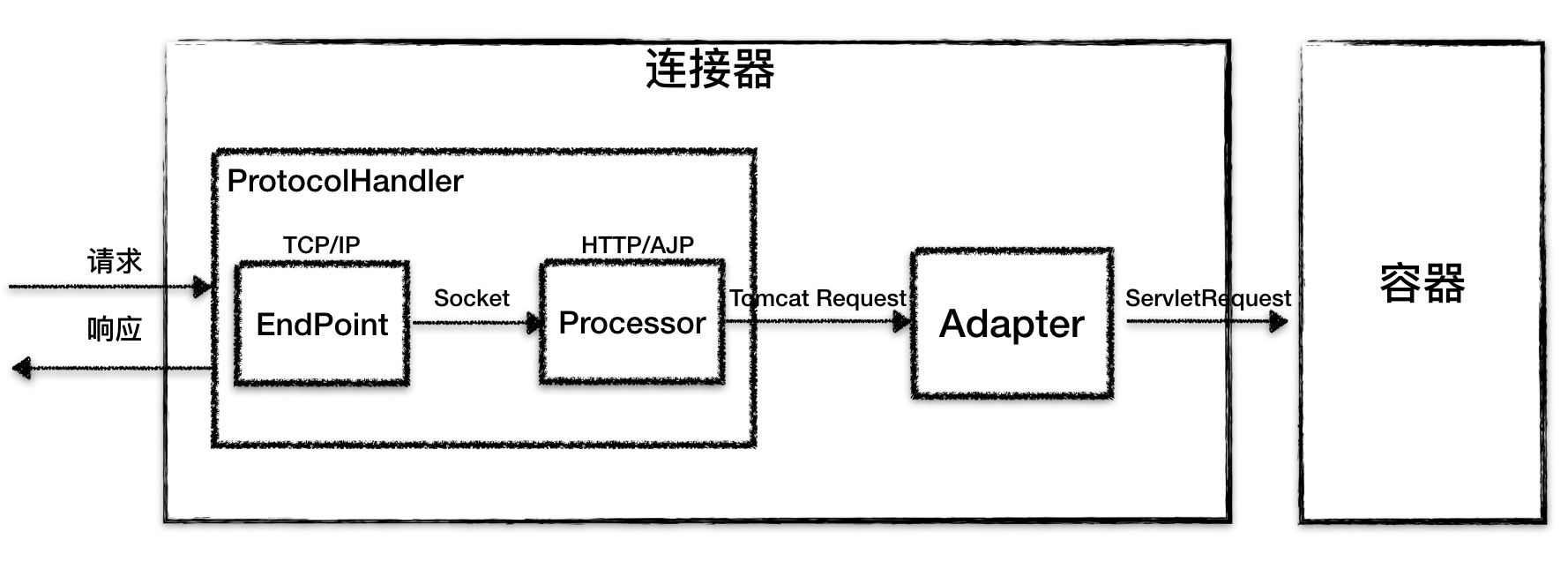
ProtocolHandler组件
Endpoint和Processor放在一起抽象成了ProtocolHandler组件,主要负责处理: 网络连接和应层协议 。
Endpoint组件
Endpoint是通信端点,是具体的Socket接收和发送处理器,是对传输层的抽象。因此Endpoint是用TCP/IP协议来进行数据读写的,本质是调用Socket接口;
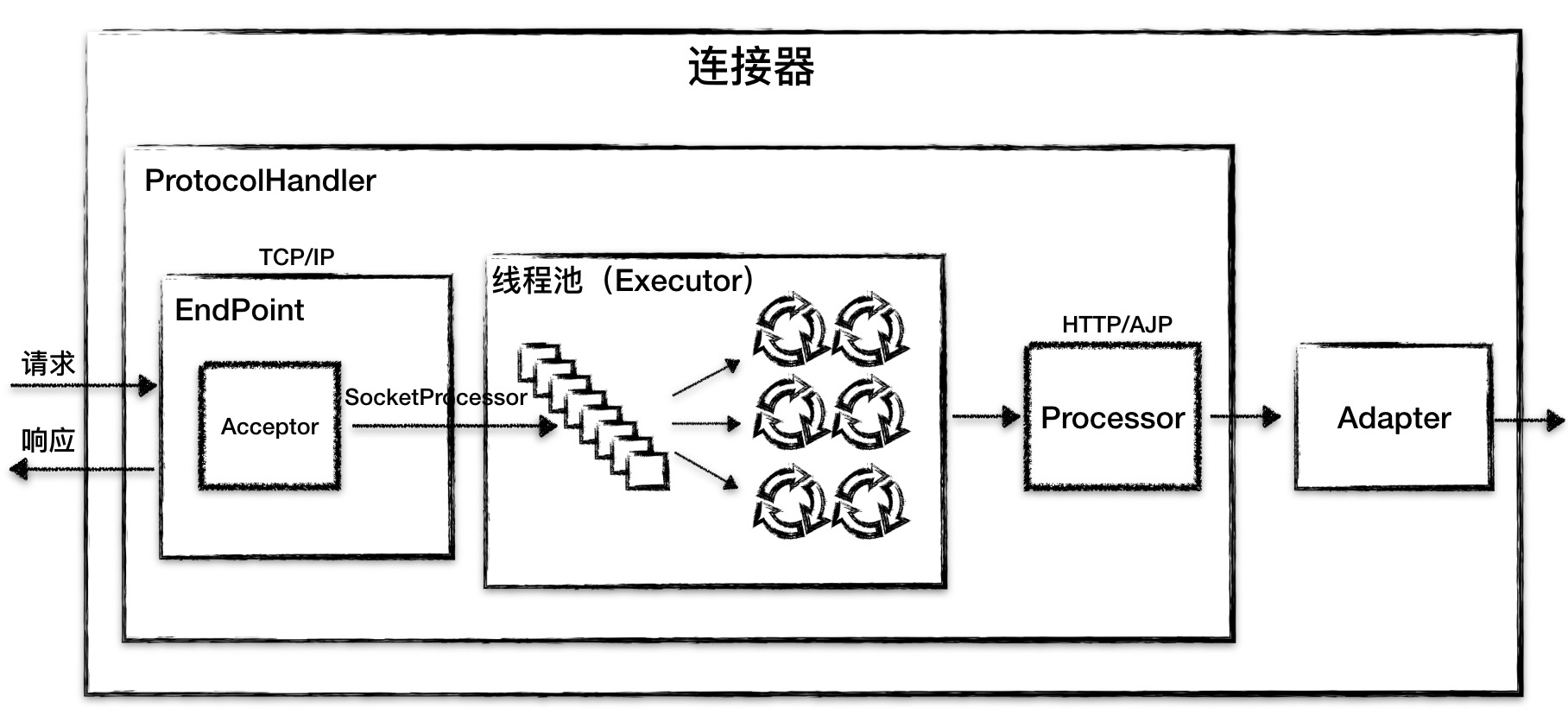
简而言之,Endpoint接收到Socket连接后,生成一个SocketProcessor任务提交到线程池进行处理,SocketProcessor的run方法将调用Processor组件进行应用层协议的解析,Processor解析后生成Tomcat Request对象,然后会调用Adapter的Service方法,方法内部通过如下代码将Request请求传递到容器中:
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);
如下图所示:
Adapter组件
由于协议的不同,Tomcat定义了自己的Request类来存放请求信息,但是这个不是标准的ServletRequest。于是需要使用Adapter将Tomcat Request对象转成ServletRequest对象,然后就可以调用容器的service方法了;
Container
Connector连接器负责外部交流,Container容器负责内部处理。也就是: 连接器处理Socket通信和应用层协议的解析,得到ServletRequest,而容器则负责处理ServletRequest 。
容器顾名思义,就是用来装东西的,Tomcat容器就是用来装载Servlet的;
Tomcat设计了4种容器:Engine、Host、Context和Wrapper。这四种容器是父子关系,如下图所示:
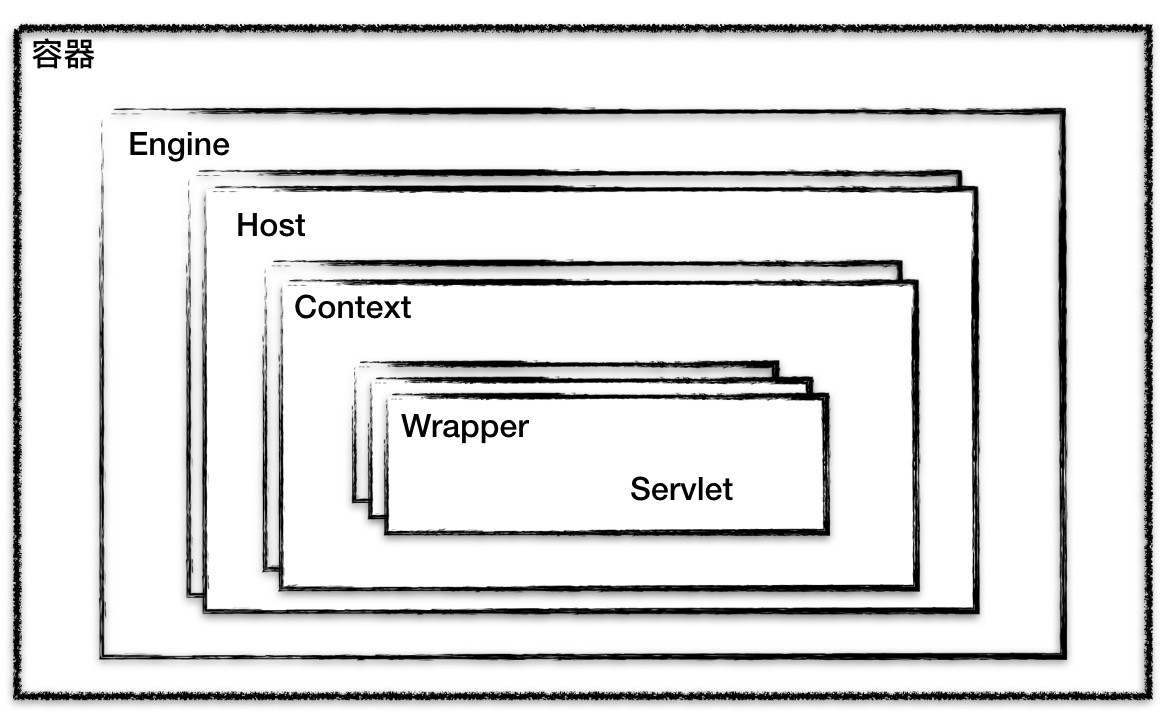
- 一个Host多个Context,一个Context包含多个Servlet;
- Wrapper表示一个Servlet,Context表示一个WEB应用程序,而一个WEB应用可以有多个Servlet;
- Host表示一个虚拟机,或者说一个站点,一个Tomcat可以配置多个站点;
- 一个站点可以部署多个WEB应用;
- Engine代表引擎,用于管理多个站点(Host),一个Service只能有一个Engine;
下面是Tomcat的配置文件,可以反应这些层次关系:
<Server port="8005" shutdown="SHUTDOWN"> // 顶层组件,可包含多个 Service,代表一个 Tomcat 实例
<Service name="Catalina"> // 顶层组件,包含一个 Engine ,多个连接器
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<!-- Define an AJP 1.3 Connector on port 8009 -->
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" /> // 连接器
// 容器组件:一个 Engine 处理 Service 所有请求,包含多个 Host
<Engine name="Catalina" defaultHost="localhost">
// 容器组件:处理指定Host下的客户端请求, 可包含多个 Context
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
// 容器组件:处理特定 Context Web应用的所有客户端请求
<Context></Context>
</Host>
</Engine>
</Service>
</Server>
请求定位Servlet的过程
Tomcat使用Mapper组件来完成请求到Wrapper中Servlet的定位的;Mapper组件的功能就是将用户请求的URL定位到一个Servlet,它的工作原理是: Mapper组件里保存了WEB应用的配置信息,也就是容器组件与访问路径的映射关系 。比如Host容器里配置的域名、Context容器里的WEB应用路径以及Wrapper容器里Servlet映射的路径。这是一个多层次的Map;
当一个请求过来,Mapper组件通过解析请求URL里的域名和路径,再到自己保存的Map里去找,就能定位到一个Servlet。 最终,一个请求URL只会定位到一个Wrapper容器,也就是一个Servlet 。
示例图如下所示:
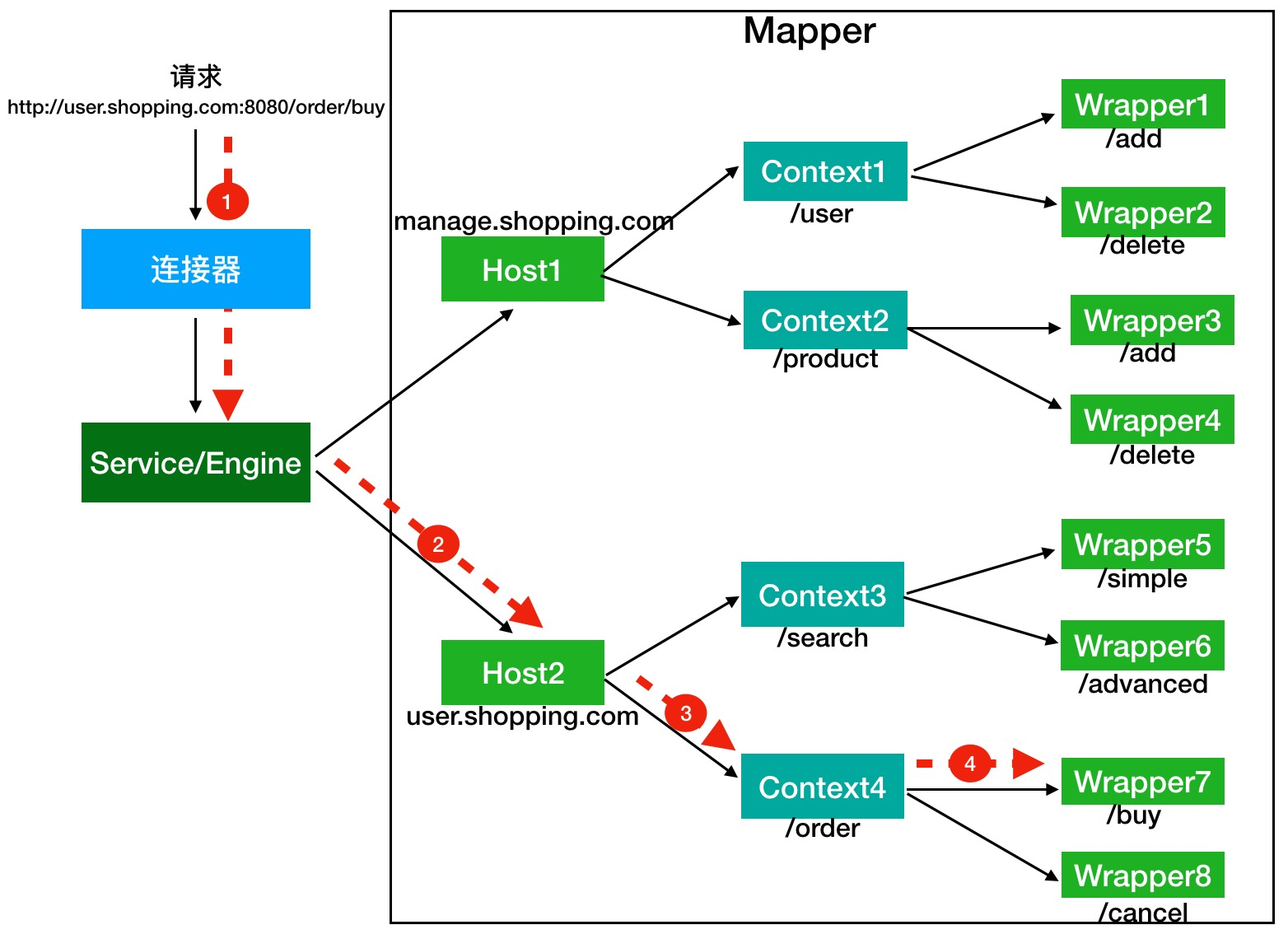
连接器中的Adapter会调用容器的service方法来执行Servlet,最先拿到请求的是Engine容器,Engine容器对请求做一些处理后,会把请求传给自己的子容器Host继续处理,以此类推,最终这个请求会传给Wrapper容器,Wrapper容器会调用最终的Servlet来处理。 整个调用过程是通过Pipeline-Valve管道进行的 。
Pipeline-Valve是责任链模式,责任链模式是指:在一个请求处理的过程中,有很多处理者一次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后再调用下一个处理者继续处理 。Valve表示一个处理点(也就是一个处理阀门),Valve中的invoke方法就是来处理请求的。
Valve的数据结构如下:
public interface Valve {
public Valve getNext();
public void setNext(Valve valve);
public void invoke(Request request, Response response)
}
Pipeline的数据结构如下:
public interface Pipeline {
public void addValve(Valve valve);
public Valve getBasic();
public void setBasic(Valve valve);
public Valve getFirst();
}
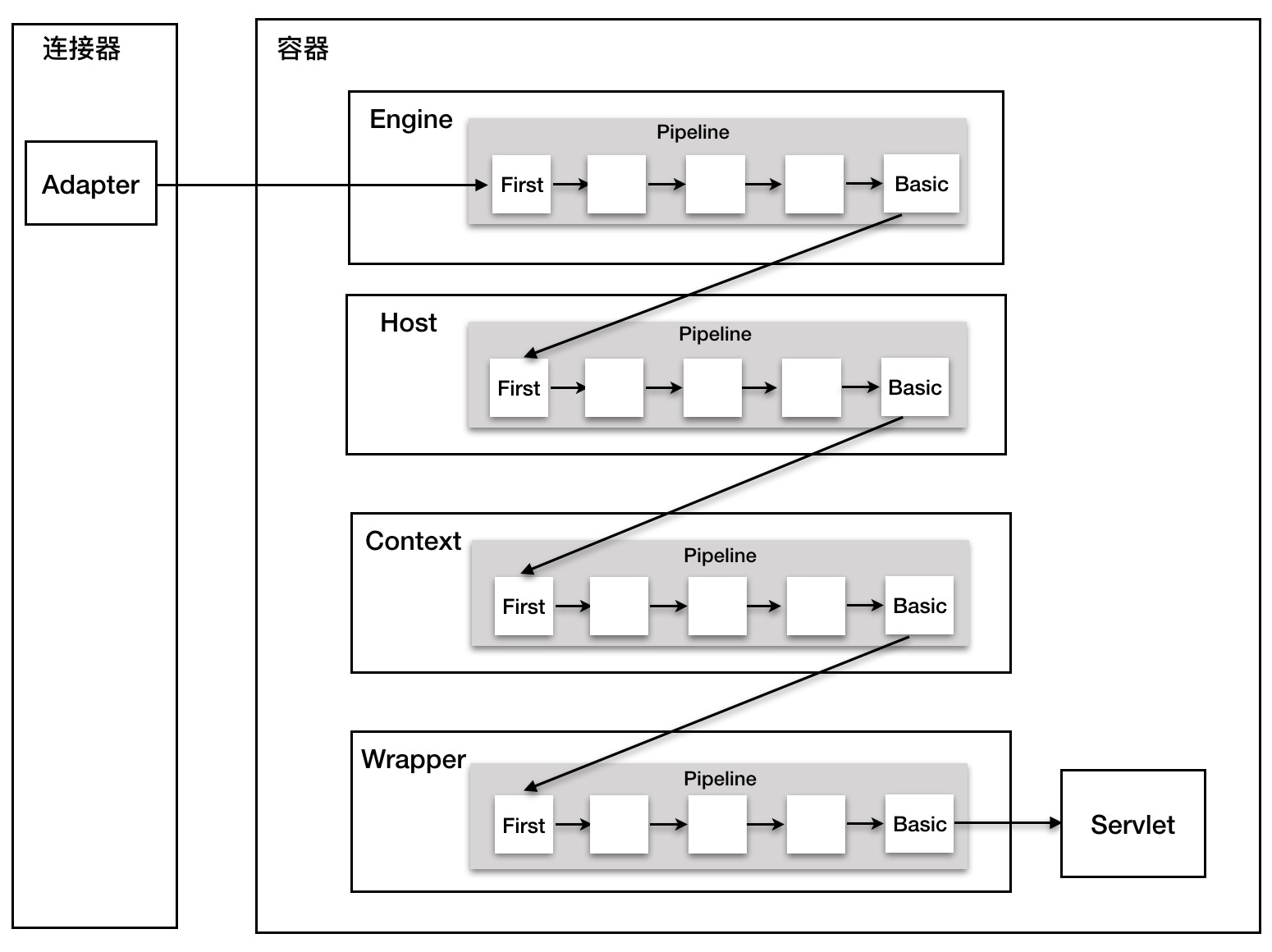
Pipeline中有addValve方法,维护了Valve链表,Valve可以插入到Pipeline中,对请求做某些处理。Pipeline中是没有invoke方法的,因为整个调用链的触发是Valve来完成的,Valve完成自己的处理后,调用getNext().invoke()来触发下一个Valve调用。
每个容器都有一个Pipeline对象,只要触发了这个Pipeline的第一个Valve,这个容器里的Pipeline中的Valve都会被调用到。
其中,Pipeline中的getBasic方法获取的Valve处于Valve链的末端,它是Pipeline中必不可少的一个Valve, 负责调用下层容器的Pipeline里的第一个Valve 。
演示图如下图所示:
而整个过程是通过连接器CoyoteAdapter中的service方法触发的,它会调用Engine的第一个Valve,如下所示:
@Override
public void service(org.apache.coyote.Request req, org.apache.coyote.Response res) {
// 省略其他代码
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(
request, response);
...
}
Wrapper容器的最后一个Valve会创建一个Filter链,并调用doFileter方法,最终会调到Servlet的service方法。
Tomcat类加载器
Tomcat自定义的类加载器WebAppClassloader为了隔离WEB应用打破了双亲委托机制,它首先尝试自己加载某个类,如果找不到再交给父类加载器,其目的是优先加载WEB应用自己定义的类。
同时,为了防止WEB应用自己的类覆盖JRE的核心类,在本地WEB应用目录下查找之前,先使用ExtClassLoader(使用双亲委托机制)去加载,这样既打破了双亲委托,同时也能安全加载类;
总结
最终得到总体的请求流程图,如下图所示:
文章作者 Pinger
上次更新 2020-05-12