集合

文章目录
概述
- 集合类也被称为 容器 ,所有的集合都位于java.util包下。
- 集合类家族主要由Collection和Map接口派生出。
- 集合相比数组的优势是:长度可变,且能存储不同类型的对象。Map还能存储映射关系。
- 集合只能存储对象,不能存储基本类型的值。
- Set代表无序不可重复,List代表有序可重复,Map代表无序不可重复键值的映射,Queue代表队列集合。
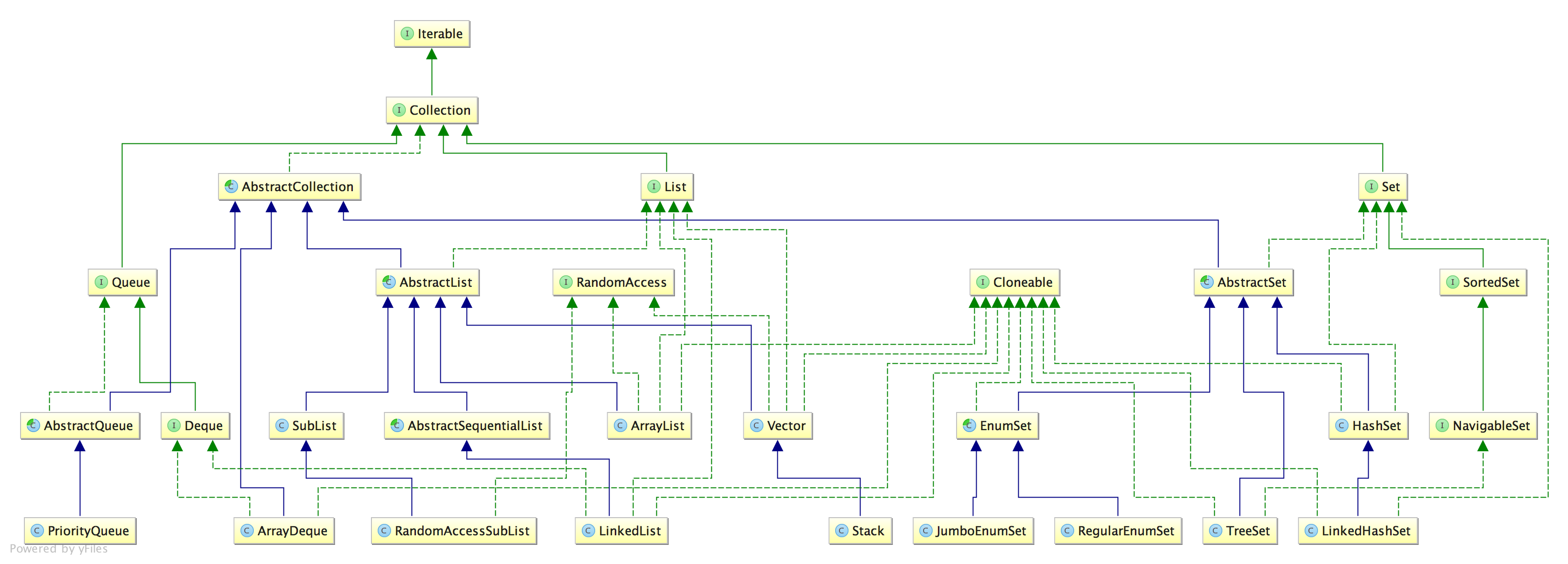
Collection的家谱如下图:
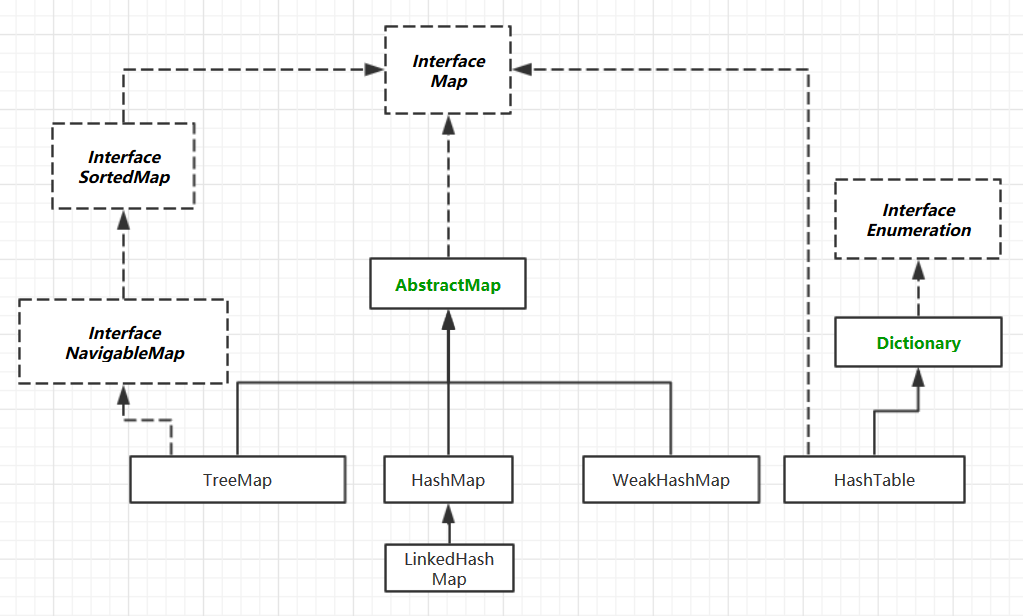
Map的家谱如下图:
Collection和Iterator
Collection是Set、List和Queue父接口,此接口定义了一些操作结合元素的基本方法。可以查看Java8的api文档。此外,Collection定义了一个返回迭代器的方法iterator(),返回一个Iterator类型的迭代器,Iterator必须依赖于Collection对象,迭代器主要如下有三个方法:
- boolean hasNext():如果被迭代的集合元素还没有被遍历,则返回true。
- Object next():返回集合里的下一个迭代对象。
- void remove():删除集合里上一次next方法返回的元素。
一个Iterator的使用例子如下(也包括了foreach的使用):
@Test
public void test_1(){
List<String> a=new ArrayList<>();
for(int i=0;i<5;i++){
a.add("我是"+i);
}
Iterator<String> iterator=a.iterator();
while(iterator.hasNext()){
String temp=iterator.next();
if(temp.equals("我是2")){
iterator.remove();
}
System.out.println(temp);
}
System.out.println("------------分割线---------------");
for(String v:a){
System.out.println(v);
}
}
输出结果如下图:
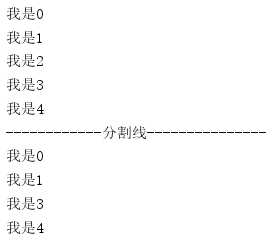
Notice: Iterator方式和foreach方式迭代过程中,不能直接对集合进行改变,否则会报错: java.util.ConcurrentModificationException ,所有的内部基于数组来实现的集合,最好用随机访问,其他的采用迭代访问。
Set集合
Set判断两个对象相等的原则是:两个对象用equals方法返回true。在此基础上再来了解HashSet、SortedSet、LinkedHashSet。
HashSet
- HashSet判断两个对象是否相等的条件是: 两个对象通过equals()方法返回true且两者的hashCode()方法返回值相等。 此外,如果两个对象的equals()返回false,但hashCode()返回的值相同,HashSet会将两个对象存储在相同的位置,使用链表结构保存,会导致性能下降。
- HashSet按照Hash算法来存储集合中的元素,具有 很好的存取和查找性能。
- 多个线程同时访问HashSet需要通过代码保证其同步。
- 集合元素可以为null
- 需要被保存到HashSet中的对象,需要重写其equals()和hashCode()方法,保证两者通过equals()方法返回为true时,两者的hashCode()方法返回也相同。
- 当HashSet中存储了对象时,此时再修改它,可能会导致它与其他对象相等(值相等),此时会导致HashSet无法准确的访问元素。
一个例子如下:
package com.test.commonClass;
import java.util.HashSet;
import java.util.Set;
public class R {
private int count;
public R(int count){
this.count=count;
}
@Override
public String toString(){
return "R[count:"+count+"]";
}
@Override
public int hashCode(){
return this.count;
}
@Override
public boolean equals(Object obj){
if(obj==this){
return true;
}else{
if(obj!=null&&obj.getClass()==this.getClass()){
R temp=(R)obj;
return temp.getCount()==this.getCount()? true:false;
}
}
return false;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public static void main(String[] args){
Set<R> set=new HashSet<>();
R a=new R(1);
set.add(a);
set.add(new R(2));
set.add(new R(3));
System.out.println(set);
//现在改变count为1的那个元素
a.setCount(3);
System.out.println(set);
//现在删除count为3的元素,将hash命中定位到第三个元素,所以删除第三个元素
set.remove(new R(3));
System.out.println(set);
//此时虽然打印出的结果中,在第一个元素那有一个count为3的元素,但是我们去找到它已经找不到了
System.out.println("是否还有count为3的元素"+set.contains(new R(3)));
System.out.println("是否还有count为1的元素"+set.contains(new R(1)));
}
}
输出结果如下图:

LindedHashSet
- LindedHashSet是HashSet的子类,也是根据元素的hash值来决定元素的存储位置。
- LindedHashSet以链表结构维护元素的次序,所以 元素是有序的 ,顺序是其添加顺序。
- LinkedHashSet性能略低于HashSet,但是迭代访问将会有很好的性能。
TreeSet
- TreeSet判断两个对象是否相等的依据是(自然排序时):两者通过compareTo()方法返回0,但是为了照顾常规思维,也得保证此时两者通过equals()方法返回true且hashCode()方法返回值相等。
- TreeSet是SortedSet接口的实现类,其集合元素处于排序状态。
- TreeSet还提供了返回第一个,最后一个,前一个,后一个元素方法;还有截取集合获得子集的方法。
- TreeSet可以使用 定制排序和自然排序。 默认情况采用自然排序。
- TreeSet采用 红黑树的数据结构来存储集合元素。
- 添加到TreeSet中的元素必须是 同样的数据类型的对象。
自然排序
自然排序要求元素的类实现了 Comparable 接口的 compareTo(Object obj) 方法。实现了该接口的类的对象就可以进行大小比较。例如 obj.compareTo(obj1) 的结果,如果返回0,则代表两者相等;如果返回正整数,则代表obj大于obj1;如果返回一个负整数,则代表obj小于obj1;常见的实现了Comparable接口的类如下:
- Character:按照字符的UNICODE值进行比较。
- Boolean:true对应的包装类实例大于false对应的包装类实例。
- String:按照字符串中字符的UNICODE值进行比较。
- Date、Time:后面的日期和时间比前面的日期和时间要大。
往TreeSet中加入元素要么需要定制排序,要么需要自然排序。而自然排序就是待加入元素的类需要实现 Comparable 接口的 compareTo(Object obj) 方法。如果使用自然排序,但是其元素没有实现Comparable接口,添加第一个元素时不会报错,但是第二个元素会报错(第二个元素需要与第一个元素进行比较,此时两者不能进行比较从而报错)。此外需要注意的地方如下:
- 就算两个对象都实现了Comparable接口,但是不是同一个类型的对象,也不能被添加到TreeSet。
- 加入到TreeSet中的对象最好是不可变对象,防止其属性被修改而导致查找元素时的比较出问题(只能查找到没有改变且不与其他改变后导致与自己重复的元素)。
定制排序
实例化一个TreeSet的时候可以传入一个匿名对象,此匿名对象是Comparator接口的实例。一个例子如下:
public class TreeSetTest {
@Test
public void test1(){
TreeSet<R> rs = new TreeSet<>(new Comparator<R>() {
@Override
public int compare(R o1, R o2) {
return o1.getCount() == o2.getCount() ? 0 : o1.getCount() > o2.getCount() ? 1 : -2;
}
});
rs.add(new R(-3));
rs.add(new R(4));
rs.add(new R(-2));
rs.add(new R(1));
rs.add(new R(3));
//输出:[R[count:-3], R[count:-2], R[count:1], R[count:3], R[count:4]]
System.out.println(rs);
}
}
Notice:此种方法同样不能在TreeSet中添加不同类型的元素。
各个Set实现类比较
- HashSet的性能总是比TreeSet好,尤其是插入和查找操作。只有当需要一个保持排序的Set时,才使用TreeSet。
- HashSet的子类LinkedHashSet,对于删除和插入操作,比HashSet慢一点(维护链表带来的额外开销造成的),不过因为是链表,所以遍历LinkedHashSet会更快。
- 总而言之:需要排序的Set,用TreeSet;一般使用HashSet;经常遍历的用LinkedHashSet。
List集合
List接口比Collection接口的迭代器多了反向迭代的功能。List集合代表有序可重复的集合,每个元素都有其对应的顺序索引。此外与Set集合相比,多了根据索引来插入,删除,替换的方法。List判断两个对象是否相等的前提是两者通过equals()方法返回true。一个例子如下:
class R{
@Override
public boolean equals(Object obj){
//无论与谁相比都是true
return true;
}
}
public class ListTest {
@Test
public void test1(){
ArrayList<String> list = new ArrayList<>();
list.add("落霞与孤鹜齐飞");
list.add("秋水共长天一色");
//因为R类的对象与谁通过equals()比较都是true,所以会输出true
System.out.println(list.contains(new R()));
//输出:[落霞与孤鹜齐飞, 秋水共长天一色]
System.out.println(list);
//当R对象与list的第一个元素通过equals()比较时,返回true,所以会在第一元素删除它
list.remove(new R());
//输出:[秋水共长天一色]
System.out.println(list);
//同上次的remove()一样,会在比较第一个元素时就把它删除了,所以下面将输出空的List集合
list.remove(new R());
//输出:[]
System.out.println(list);
}
}
ListIterator
与Set不同的是,List提供一个可以反向迭代的ListIterator迭代器。该接口继承于Iterator接口,在其基础上增加了如下方法:
- boolean hasPrevious():该迭代器关联的集合是否有上一个元素。
- Object previous():返回该迭代器的上一个元素。
- void add():在指定位置插入一个元素。
一个使用例子如下:
@Test
public void test2(){
ArrayList<String> list = new ArrayList<>();
list.add("落霞与孤鹜齐飞");
list.add("秋水共长天一色");
list.add("关山难越");
list.add("谁背失路之人");
list.add("哀吾生之须臾");
list.add("羡长江之无穷");
ListIterator<String> iterator=list.listIterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
//接下来反向迭代(先正向迭代,指针到了后面才能反向迭代)
while(iterator.hasPrevious()){
System.out.println(iterator.previous());
}
}
输出截图如下:

ArrayList
ArrayList是一个基于数组的实现的List类,所以随机访问性能比较好。虽然ArrayList相对数组而言,可以动态的改变元素的个数,但是其实实例化时,也可以指定ArrayList的个数(不指定默认为10)。后面如果超出了这个数量,则会动态分配大小,但是如果提前就知道了需要存储比较多的元素时,可以直接调用ArrayList的 ensureCapacity() 方法来一次性地增加initialCapacity,可以减少重新分配的次数,从而提高性能。此外,可以调用 trimToSize() 方法来调整其内部的数组长度为当前元素个数,从而减少了ArrayList占用的空间。一个实例代码如下:
@Test
public void test3(){
//实例化时指定List集合的initialCapacity,长度超出时会自动增长。
//如果不写,默认为10
ArrayList<Integer> list1 = new ArrayList<>(10);
ArrayList<String> list2 = new ArrayList<>();
//当一开始不知道需要多大的List空间时,可以之后利用其ensureCapacity()方法来指定其元素个数
//这样避免总是自动分配,提高性能
list2.ensureCapacity(100);
for(int i=0;i<40;i++){
list2.add(String.valueOf(i));
}
list2.trimToSize();
}
此外还有一个不可变长度的ArrayList,就是Arrays.ArrayList类(这个ArrayList是Arrays的内部类),可以通过调用Arrays的asList()方法来将一个数组转换成其内部类ArraysList的对象。此对象不可添加和删除元素。实例代码如下:
@Test
public void test4(){
String[] a=new String[]{"one","two","three"};
List<String> list = Arrays.asList(a);
//下面的操作会报错
System.out.println(list.add("four")+","+list.remove("one"));
}
Queue集合
Queue主要是为了模拟队列这种数据结构。常用到的有Deque接口的实现类ArrayDeque和LinkedDeque。Deque代表双端队列,如果需要使用到栈这种数据结构,推荐使用ArrayDeque和LinkedDeque。前者随机访问性能比较好,后者迭代访问性能比较好。两者主要方法可以查看api文档。
Map集合
Map就是存储具有映射关系的数据,就是所谓的键值对。Map的key不允许重复,但是允许为null(也只能存在一个)。Map判断键值对的key相等的规则也是两者通过equals()方法返回true则认为它们相等。其实Java是先实现了Map再实现了Set,Set就是键值对中值为null的Map。Map接口常用方法如下:
- Set entrySet():返回Map中包含的键值对所组成的Set集合,每个集合元素都是Map.Entry对象。
- boolean isEmpty():判断此Map是否为空。
- Set keySet():返回该Map中所有key组成的Set集合。
- Collection values():返回该Map中所有键值对的值组成的Collection。
其中Map.Entry的主要几个方法如下:
- Object getKey():返回该键值对的键。
- Object getValue():返回该键值对的值。
- Object setValue():设置该键值对的值,并返回新设置的值。
HashMap
- Map接口常用的实现类就是HashMap了,但 它不是一个线程安全的类, 可以使用Collections工具类将HashMap变成线程安全来使用。
- HashMap允许最多存在一个键为null的键值对(也允许将键值对的值设置为null,这个允许多个)
- 存放在HashMap中的键值对的键必须实现equals()和hashCode()方法,保证两者通过equals()方法返回true时,两者的hashCode()返回的值相等。
- HashMap键值对的值相等的原则是两者通过equals()方法返回true。
- 尽量不要使用可变对象作为HashMap的键。
一个HashMap有关的综合例子如下:
@Test
public void test5(){
Map<String,Integer> map=new HashMap<>();
System.out.println(map.put("嘻嘻",0));
System.out.println(map.put(new String("哈哈"),1));
//已存在“哈哈”键的映射,此时将会替换旧值,并返回旧值(没有发生替换是返回的是null)
System.out.println(map.put(new String("哈哈"),2));
//存放键为null的映射
System.out.println(map.put(null,3));
//存放值为null的映射
System.out.println(map.put("哇呜",null));
//再次放入一个已存在键的映射,任然会替换这个键的值,返回被替换的旧值
System.out.println(map.put(null,4));
System.out.println("Map大小:"+map.size());
System.out.println("Map元素:"+map);
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Iterator<Map.Entry<String, Integer>> iterator = entries.iterator();
System.out.println("-----------------遍历HashMap方式一:通过Entry(速度最快)------------------");
while(iterator.hasNext()){
Map.Entry tmp=iterator.next();
System.out.println(tmp.getKey()+"::::"+tmp.getValue());
}
System.out.println("---------------遍历HashMap方式二:利用keySet(折中了下,速度慢)------------------");
Iterator<String> iterator1 = map.keySet().iterator();
while (iterator1.hasNext()){
String key=iterator1.next();
System.out.println(key+"::::"+map.get(key));
}
//以上两种遍历方式都可以将迭代器方式换成foreach方式。(foreach其实也是调用的iterator)
//换成foreach其实和用迭代器速度差不多,但foreach更加简洁易懂
//需要注意的是,只有基于链表实现的容器,遍历才需要避免使用get方式(可用foreach和iterator方式)
}
运行结果如下:

LinkedHashMap
LinkedHashMap是HashMap的子类,此类需要维护元素插入的顺序,以链表来维护内部的顺序,迭代访问时具有不错的性能。一个案例如下:
@Test
public void test6(){
LinkedHashMap<String, Integer> map = new LinkedHashMap<>();
map.put("一",1);
map.put("二",2);
map.put("三",3);
map.put("四",4);
map.put("五",5);
for (Map.Entry<String,Integer> v:map.entrySet()){
//对于内部用链表维护的容器,避免使用get方式遍历
System.out.println(v.getKey()+"::::"+v.getValue());
}
}
运行结果如下:
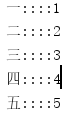
Properties类读写属性文件
Hashtable是一个和HashMap很类似类,Hashtable不允许存在键或值为null的映射,其他的和HashMap差不多(但是过于古老,不建议使用)。而Properties则是Hashtable的一个子类。Properties可以将Map对象和属性文件关联起来,可以把Map的键值对写入属性文件中,也可以把属性文件中的 属性=属性值 加载到Map中,同时由于属性文件中的“属性”和“属性值”都是字符串类型的,所以Properties中的键值对都是String类型的。此类提供常用的三个方法:
- String getProperty(String key):获取指定键的属性值。
- String getPropery(String key,String defaultValue):获取指定键的属性值,如果不存在,则添加此键的默认值。
- Object setProperty(String key,String value):设置属性值。
- void load(InputStream inStream):从属性文件加载键值对,追加到当前Properties对象。
- void store(OutputStream outStream,String comments):将Properties对象中的键值对输出到指定的属性文件中。comments表示注释。
一个测试代码如下:
@Test
public void test7() throws IOException {
Properties properties = new Properties();
properties.setProperty("username","root");
properties.setProperty("password","123456");
FileOutputStream out = new FileOutputStream("res/properties/test.properties");
properties.store(out,"just a test~~");
//再创建另一个Properties对象,加载刚在创建的属性文件
Properties properties1 = new Properties();
properties1.setProperty("driver","mysql8");
properties1.load(new FileInputStream("res/properties/test.properties"));
//将输出:{password=123456, driver=mysql8, username=root},可将load是追加方式,而不是覆盖方式
System.out.println(properties1);
//再将第二个properties对象写入到xml文件中
properties1.storeToXML(new FileOutputStream("res/xml/test.xml"),"只是测试","UTF-8");
}
res/properties/test.properties内容如下图:
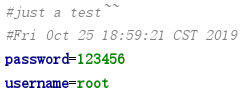
res/xml/test.xml内容如下图:
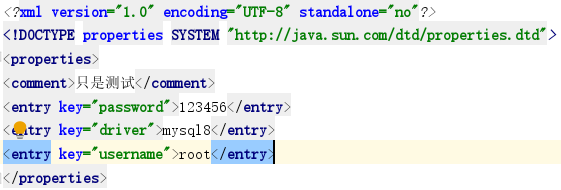
SortedMap接口和TreeMap实现类
Map接口派生出一个SortedMap接口,此接口有一个实现类TreeMap。每个键值对作为一个红黑树的节点,TreeMap里存放的键值对的键的要求和TreeSet一样。具体的往前TreeSet看便知。
IdentityHashMap
这个Map实现类的实现机制与HashMap基本相似,但是这个Map比较两个键相等的规则是严格相等(两者通过 == 运算符得到true时)。
一个例子如下:
@Test
public void test8(){
IdentityHashMap<String, Integer> map = new IdentityHashMap<>();
map.put(new String("pinger"),18);
//由于IdentityHashMap判断两个key相等的原则时两者严格相等,所以下面的input能够被添加成功。
map.put(new String("pinger"),20);
//输出:{pinger=20, pinger=18}
System.out.println(map);
}
各个Map实现类比较
- HashMap和Hashtable效率差不多,前者线程不安全,后者线程安全。
- TreeMap比HashMap和Hashtable慢,但是其键时有序的(可以利用二分法查找需要的键)。
- LinkedHashMap比HashMap慢一点,通过链表维护添加元素的顺序。
- IdentityHashMap除了“键严格相等”外无其他特点。
Collections工具类
Collections工具类提供了大量对集合元素进行操作的方法。这些操作去查看java的API文档。此外Collections工具类有两个需要注意的功能:
- 同步控制
- 设置不可变集合
创建线程同步的集合的实例如下:
@Test
public void test9(){
Set<Object> set = Collections.synchronizedSet(new HashSet<>());
List<Object> list = Collections.synchronizedList(new ArrayList<>());
Map<Object, Object> map = Collections.synchronizedMap(new HashMap<>());
Collection<Object> collection = Collections.synchronizedCollection(new TreeSet<>());
}
设置不可变集合的实例如下:
@Test
public void test10(){
//创建一个空的、不可改变的List集合
List<Object> list = Collections.emptyList();
//创建只有一个元素的、不可改变的Set集合
Set<Integer> singleton = Collections.singleton(1);
Map map=new HashMap();
map.put("一",1);
map.put("二",2);
//返回上面创建的map的不可变版本
Map map1 = Collections.unmodifiableMap(map);
}
文章作者 Pinger
上次更新 2019-10-18